浏览器是再熟悉不过的东西了,几乎每个人用过,比如 Chrome、FireFox、Safari,尤其是我们程序员,可谓开发最强辅助,摸鱼最好的伴侣。
浏览器能干的事儿,无头浏览器都能干,而且很多时候比标准浏览器还要更好用,而且能实现一些很好玩儿的功能,我们能借助无头浏览器比肩标准浏览器强大的功能,而且又能灵活的用程序控制的特性,做出一些很有意思的产品功能来,稍后我们细说。
什么是浏览器
关于浏览器还有一个很好玩儿的梗,对于一些对计算机、对互联网不太了解的同学,你跟他说浏览器,他/她就默认是百度了,因为好多小白的浏览器都设置了百度为默认页面。所以很多小白将浏览器和搜索引擎(99%是百度)划等号了。

浏览器里我百分之99的时间都是用 Chrome,不过有一说一,这玩意是真耗内存,我基本上是十几、二十几个的 tab 开着,再加上几个 IDEA 进程,16G 的内存根本就不够耗的。
以 Chrome 浏览器为例,Chrome 由以下几部分组成:
- 渲染引擎(Rendering Engine):Chromium使用的渲染引擎主要有两个选项:WebKit和Blink。WebKit是最初由苹果开发的渲染引擎,后来被Google采用并继续开发。Blink则是Google从WebKit分支出来并进行独立开发的渲染引擎,目前Chromium主要使用Blink作为其默认的渲染引擎。
- JavaScript引擎(JavaScript Engine):Chromium使用V8引擎作为其JavaScript引擎。V8是由Google开发的高性能JavaScript引擎,它负责解析和执行网页中的JavaScript代码。
- 网络栈(Network Stack):Chromium的网络栈负责处理网络通信。它支持各种网络协议,包括HTTP、HTTPS、WebSocket等,并提供了网络请求、响应处理和数据传输等功能。
- 布局引擎(Layout Engine):Chromium使用布局引擎来计算网页中元素的位置和大小,并确定它们在屏幕上的布局。布局引擎将CSS样式应用于DOM元素,并计算它们的几何属性。
- 绘制引擎(Painting Engine):绘制引擎负责将网页内容绘制到屏幕上,生成最终的图像。它使用图形库和硬件加速技术来高效地进行绘制操作。
- 用户界面(User Interface):Chromium提供了用户界面的支持,包括地址栏、标签页、书签管理、设置等功能。它还提供了扩展和插件系统,允许用户根据自己的需求进行个性化定制。
- 其他组件:除了上述主要组件外,Chromium还包括其他一些辅助组件,如存储系统、安全模块、媒体处理、数据库支持等,以提供更全面的浏览器功能。
Chrome 浏览器光源码就有十几个G,2000多万行代码,可见,要实现一个功能完善的浏览器是一项浩大的工程。
什么是无头浏览器
无头浏览器(Headless Browser)是一种浏览器程序,没有图形用户界面(GUI),但能够执行与普通浏览器相似的功能。无头浏览器能够加载和解析网页,执行JavaScript代码,处理网页事件,并提供对DOM(文档对象模型)的访问和操作能力。
与传统浏览器相比,无头浏览器的主要区别在于其没有可见的窗口或用户界面。这使得它在后台运行时,不会显示实际的浏览器窗口,从而节省了系统资源,并且可以更高效地执行自动化任务。
常见的无头浏览器包括Headless Chrome(Chrome的无头模式)、PhantomJS、Puppeteer(基于Chrome的无头浏览器库)等。它们提供了编程接口,使开发者能够通过代码自动化控制和操作浏览器行为。
无头浏览器其实就是看不见的浏览器,所有的操作都要通过代码调用 API 来控制,所以浏览器能干的事儿,无头浏览器都能干,而且很多事儿做起来比标准的浏览器更简单。
我举几个常用的功能来说明一下无头浏览器的主要使用场景
- 自动化测试: 无头浏览器可以模拟用户行为,执行自动化测试任务,例如对网页进行加载、表单填写、点击按钮、检查页面元素等。
- 数据抓取: 无头浏览器可用于爬取网页数据,自动访问网站并提取所需的信息,用于数据分析、搜索引擎优化等。
- 屏幕截图: 无头浏览器可以加载网页并生成网页的截图,用于生成快照、生成预览图像等。
- 服务器端渲染: 无头浏览器可以用于服务器端渲染(Server-side Rendering),将动态生成的页面渲染为静态HTML,提供更好的性能和搜索引擎优化效果。
- 生成 PDF 文件:使用浏览器自带的生成 PDF 功能,将目标页面转换成 PDF 。
使用无头浏览器做一些好玩的功能
开篇就说了使用无头浏览器可以实现一些好玩儿的功能,这些功能别看不大,但是使用场景还是很多的,有些开发者就是抓住这些小功能,开发出好用的产品,运气好的话还能赚到钱,尤其是在国外市场。(在国内做收费的产品确实不容易赚到钱)
下面我们就来介绍两个好玩儿而且有用的功能。
前面的自动化测试、服务端渲染就不说了。
自动化测试太专业了,一般用户用不到,只有开发者或者测试工程师用。
服务端渲染使用无头浏览器确实没必要,因为有太多成熟的方案了,连 React 都有服务端渲染的能力(RSC)。
网页截图功能
我们可能见过一些网站提供下载文字卡片或者图文卡片的功能。比如读到一段想要分享的内容,选中之后将文本端所在的区域生成一张图片。

其实就是通过调用浏览器自身的 API page.screenshot,可以对整个页面或者选定的区域生成图片。
通过这个方法,我们可以做一个浏览器插件,用户选定某个区域后,直接生成对应的图片。这类功能在手机APP上很常见,在浏览器上一搬的网站都不提供。
说到这儿好像和无头浏览器都没什么关系吧,这都是标准浏览器中做的事儿,用户已经打开了页面,在浏览器上操作自己看到的内容,顺理成章。
但是如果这个操作是批量的呢,或者是在后台静默完成的情况呢?
那就需要无头浏览器来出手了,无头浏览器虽然没有操作界面,但是也具备绘制引擎的完整功能,仍然可以生成图像,利用这个功能,就可以批量的、静默生成图像了,并且可以截取完整的网页或者部分区域。
Puppeteer 是无头浏览器中的佼佼者,提供了简单好用的 API ,不过是 nodejs 版的。
如果是用 Java 开发的话,有一个替代品,叫做 Jvppeteer,提供了和 Puppeteer 几乎一模一样的 API。
下面这段代码就展示了如何用 Jvppeteer 来实现网页的截图。
下面这个方法是对整个网页进行截图,只需要给定网页 url 和 最终的图片路径就可以了。
public static boolean screenShotWx(String url, String path) throws IOException, ExecutionException, InterruptedException {
BrowserFetcher.downloadIfNotExist(null);
ArrayList<String> arrayList = new ArrayList<>();
// MacOS 要这样写,指定Chrome的位置
String executablePath = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome";
LaunchOptions options = new LaunchOptionsBuilder().withExecutablePath(executablePath).withArgs(arrayList).withHeadless(true).withIgnoreHTTPSErrors(true).build();
// Windows 和 Linux 这样就可以,不用指定 Chrome 的安装位置
//LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).withIgnoreHTTPSErrors(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
arrayList.add("--ignore-certificate-errors");
arrayList.add("--disable-gpu");
arrayList.add("--disable-web-security");
arrayList.add("--disable-infobars");
arrayList.add("--disable-extensions");
arrayList.add("--disable-bundled-ppapi-flash");
arrayList.add("--allow-running-insecure-content");
arrayList.add("--mute-audio");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.setJavaScriptEnabled(true);
page.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36 Edg/83.0.478.37");
page.setCacheEnabled(true);
page.onConsole((msg) -> {
log.info("==> {}", msg.text());
});
PageNavigateOptions pageNavigateOptions = new PageNavigateOptions();
pageNavigateOptions.setTimeout(1000000);
//dom加载完毕就算导航完成
pageNavigateOptions.setWaitUntil(Collections.singletonList("domcontentloaded"));
page.goTo(url, pageNavigateOptions, true);
autoScroll(page);
ElementHandle body = page.$("body");
double width = body.boundingBox().getWidth();
double height = body.boundingBox().getHeight();
Viewport viewport = new Viewport();
viewport.setWidth((int) width); // 设置视口宽度
viewport.setHeight((int) height + 100); // 设置视口高度
page.setViewport(viewport);
ScreenshotOptions screenshotOptions = new ScreenshotOptions();
screenshotOptions.setType("jpeg");
screenshotOptions.setFullPage(Boolean.FALSE);
//screenshotOptions.setClip(clip);
screenshotOptions.setPath(path);
screenshotOptions.setQuality(100);
// 或者转换为 base64
//String base64Str = page.screenshot(screenshotOptions);
//System.out.println(base64Str);
browser.close();
return true;
}
一个自动滚屏的方法。
虽然可以监听页面上的事件通知,比如 domcontentloaded,文档加载完成的通知,但是很多时候并不能监听到网页上的所有元素都加载完成了。对于那些滚动加载的页面,可以用这种方式模拟完全加载,加载完成之后再进行操作就可以了。
使用自动滚屏的操作,可以模拟我们人为的在界面上下拉滚动条的操作,随着滚动条的下拉,页面上的元素会自然的加载,不管是同步的还有延迟异步的,比如图片、图表等。
private static void autoScroll(Page page) {
if (page != null) {
try {
page.evaluate("() => {\n" +
" return new Promise((resolve, reject) => {\n" +
" //滚动的总高度\n" +
" let totalHeight = 0;\n" +
" //每次向下滚动的高度 500 px\n" +
" let distance = 500;\n" +
" let k = 0;\n" +
" let timeout = 1000;\n" +
" let url = window.location.href;\n" +
" let timer = setInterval(() => {\n" +
" //滚动条向下滚动 distance\n" +
" window.scrollBy(0, distance);\n" +
" totalHeight += distance;\n" +
" k++;\n" +
" console.log(`当前第${k}次滚动,页面高度: ${totalHeight}`);\n" +
" //页面的高度 包含滚动高度\n" +
" let scrollHeight = document.body.scrollHeight;\n" +
" //当滚动的总高度 大于 页面高度 说明滚到底了。也就是说到滚动条滚到底时,以上还会继续累加,直到超过页面高度\n" +
" if (totalHeight >= scrollHeight || k >= 200) {\n" +
" clearInterval(timer);\n" +
" resolve();\n" +
" window.scrollTo(0, 0);\n" +
" }\n" +
" }, timeout);\n" +
" })\n" +
" }");
} catch (Exception e) {
}
}
}
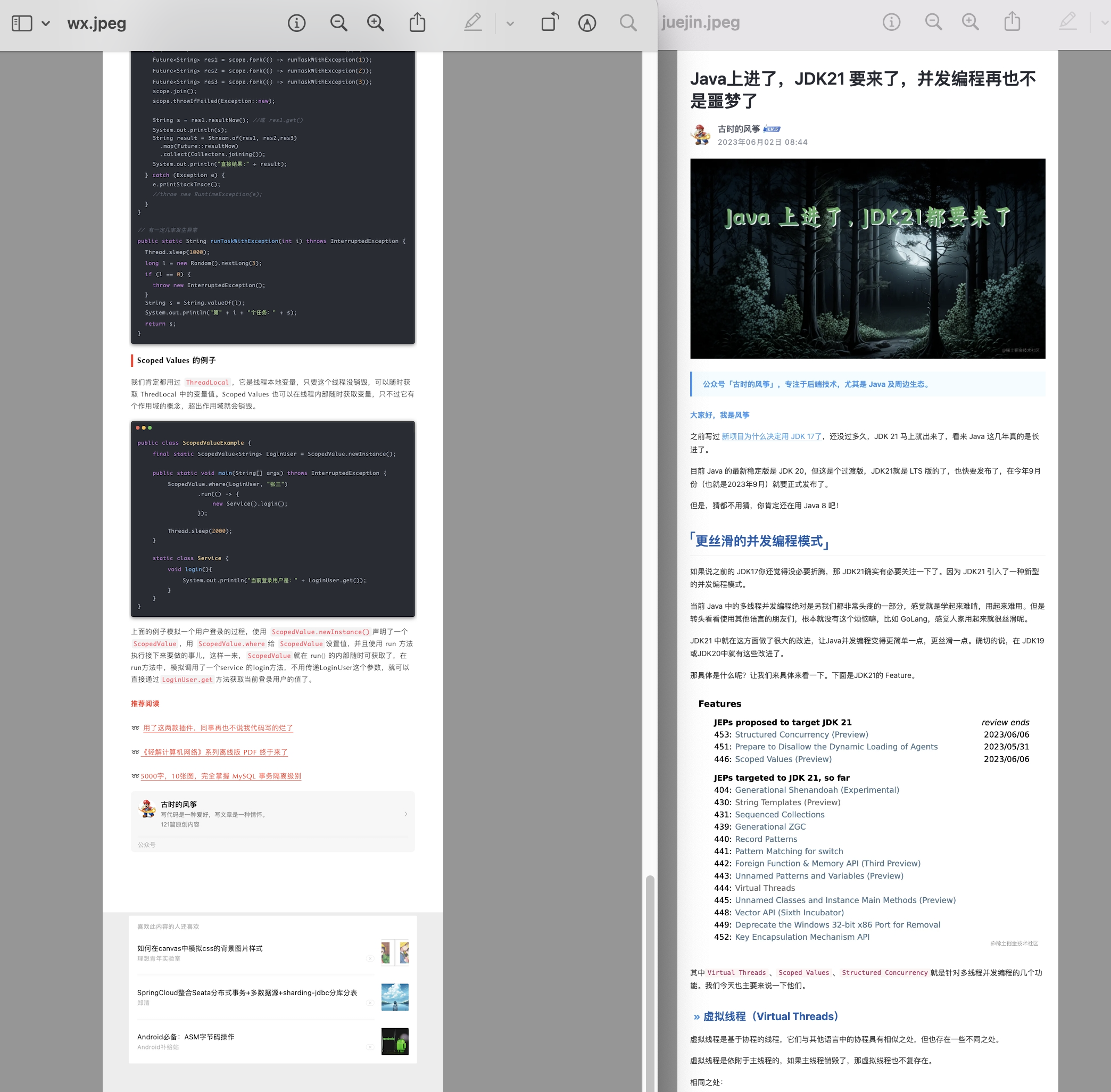
调用截图方法截图,这里是对一篇公众号文章进行整个网页的截图。
public static void main(String[] args) throws Exception {
screenShotWx("https://mp.weixin.qq.com/s/MzCyWqcH1TCytpnHI8dVjA", "/Users/fengzheng/Desktop/PICTURE/wx.jpeg");
}
或者也可以截取页面中的部分区域,比如某篇文章的正文部分,下面这个方法是截图一个博客文章的正文部分。
public static boolean screenShotJueJin(String url, String path) throws IOException, ExecutionException, InterruptedException {
BrowserFetcher.downloadIfNotExist(null);
ArrayList<String> arrayList = new ArrayList<>();
String executablePath = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome";
LaunchOptions options = new LaunchOptionsBuilder().withExecutablePath(executablePath).withArgs(arrayList).withHeadless(true).withIgnoreHTTPSErrors(true).build();
//LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).withIgnoreHTTPSErrors(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
PageNavigateOptions pageNavigateOptions = new PageNavigateOptions();
pageNavigateOptions.setTimeout(1000000);
//dom加载完毕就算导航完成
pageNavigateOptions.setWaitUntil(Collections.singletonList("domcontentloaded"));
page.goTo(url, pageNavigateOptions, true);
WaitForSelectorOptions waitForSelectorOptions = new WaitForSelectorOptions();
waitForSelectorOptions.setTimeout(1000 * 15);
waitForSelectorOptions.setVisible(Boolean.TRUE);
// 指定截图的区域
ElementHandle elementHandle = page.waitForSelector("article.article", waitForSelectorOptions);
Clip clip = elementHandle.boundingBox();
Viewport viewport = new Viewport();
ElementHandle body = page.$("body");
double width = body.boundingBox().getWidth();
viewport.setWidth((int) width); // 设置视口宽度
viewport.setHeight((int) clip.getHeight() + 100); // 设置视口高度
page.setViewport(viewport);
ScreenshotOptions screenshotOptions = new ScreenshotOptions();
screenshotOptions.setType("jpeg");
screenshotOptions.setFullPage(Boolean.FALSE);
screenshotOptions.setClip(clip);
screenshotOptions.setPath(path);
screenshotOptions.setQuality(100);
// 或者生成图片的 base64编码
String base64Str = page.screenshot(screenshotOptions);
System.out.println(base64Str);
return true;
}
调用方式:
public static void main(String[] args) throws Exception {
screenShotJueJin("https://juejin.cn/post/7239715628172902437", "/Users/fengzheng/Desktop/PICTURE/juejin.jpeg");
}
最后的效果是这样的,可以达到很清晰的效果。
网页生成 PDF 功能
这个功能可太有用了,可以把一些网页转成离线版的文档。有人说直接保存网页不就行了,除了程序员,大部分人还是更能直接读 PDF ,而不会用离线存储的网页。
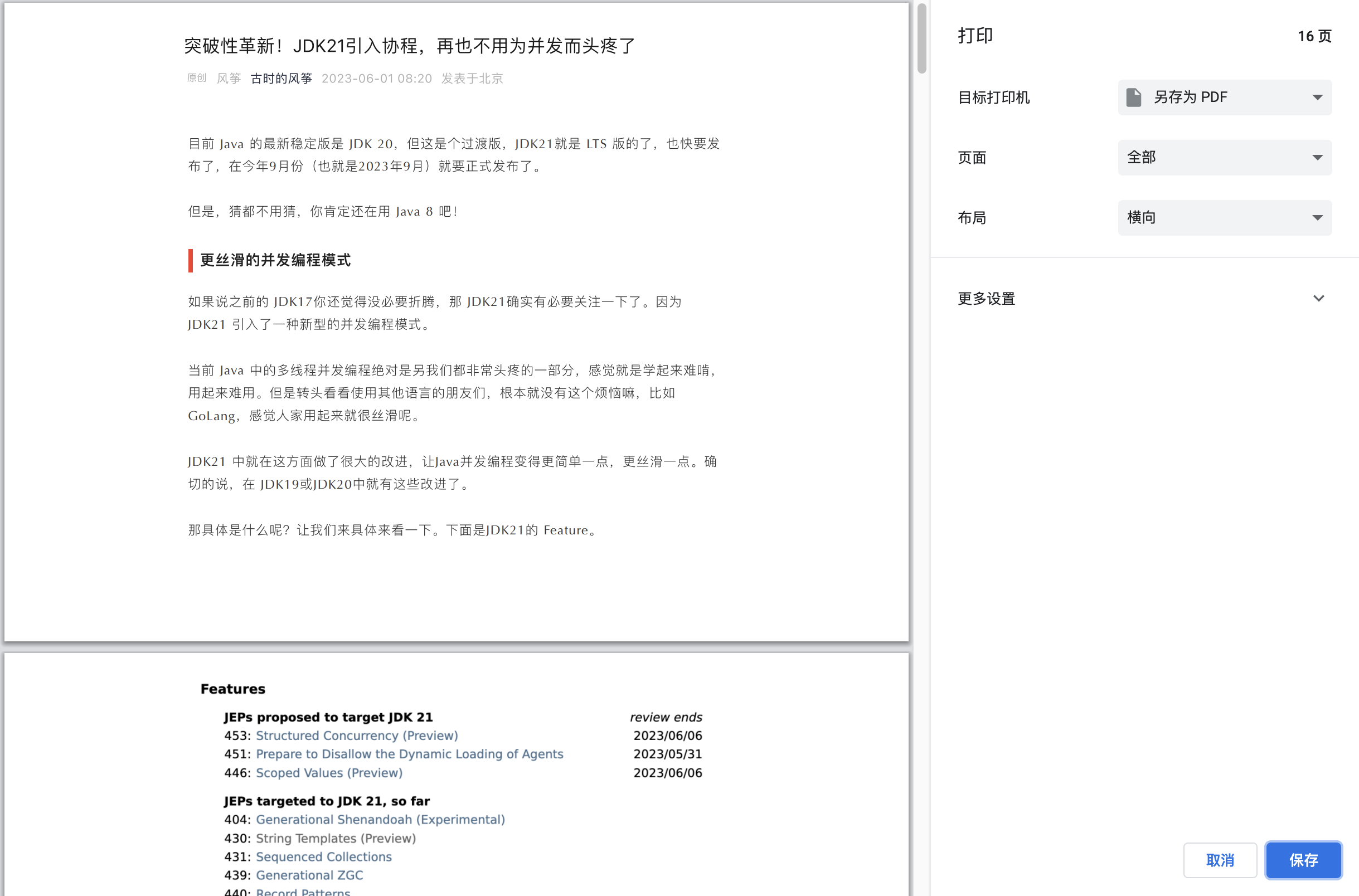
我们可以在浏览器上使用浏览器的「打印」功能,用来将网页转换成 PDF 格式。
但这是直接在页面上操作,如果是批量操作呢,比如想把一个专栏的所有文章都生成 PDF呢,就可以用无头浏览器来做了。
有的同学说,用其他的库也可以呀,Java 里面有很多生成 PDF 的开源库,可以把 HTML 转成 PDF,比如Apache PDFBox、IText 等,但是这些库应对一般的场景还行,对于那种页面上有延迟加载的图表啊、图片啊、脚本之类的就束手无策了。
而无头浏览器就可以,你可以监听页面加载完成的事件,可以模拟操作,主动触发页面加载,甚至还可以在页面中添加自定义的样式、脚本等,让生成的 PDF 更加完整、美观。
下面这个方法演示了如何将一个网页转成 PDF 。
public static boolean pdf(String url, String savePath) throws Exception {
Browser browser = null;
Page page = null;
try {
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList<String> arrayList = new ArrayList<>();
// MacOS
String executablePath = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome";
LaunchOptions options = new LaunchOptionsBuilder().withExecutablePath(executablePath).withArgs(arrayList).withHeadless(true).withIgnoreHTTPSErrors(true).build();
// windows 或 linux
//LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).withIgnoreHTTPSErrors(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
arrayList.add("--ignore-certificate-errors");
arrayList.add("--disable-gpu");
arrayList.add("--disable-web-security");
arrayList.add("--disable-infobars");
arrayList.add("--disable-extensions");
arrayList.add("--disable-bundled-ppapi-flash");
arrayList.add("--allow-running-insecure-content");
arrayList.add("--mute-audio");
browser = Puppeteer.launch(options);
page = browser.newPage();
page.onConsole((msg) -> {
log.info("==> {}", msg.text());
});
page.setViewport(viewport);
page.setJavaScriptEnabled(true);
page.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36 Edg/83.0.478.37");
page.setCacheEnabled(true);
//设置参数防止检测
page.evaluateOnNewDocument("() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => undefined } }) }");
page.evaluateOnNewDocument("() =>{ window.navigator.chrome = { runtime: {}, }; }");
page.evaluateOnNewDocument("() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }");
page.evaluateOnNewDocument("() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }");
PageNavigateOptions pageNavigateOptions = new PageNavigateOptions();
pageNavigateOptions.setTimeout(1000000);
//dom加载完毕就算导航完成
pageNavigateOptions.setWaitUntil(Collections.singletonList("domcontentloaded"));
page.goTo(url, pageNavigateOptions, true);
// 添加自定义演示
StyleTagOptions styleTagOptions1 = new StyleTagOptions();
styleTagOptions1.setContent("html {-webkit-print-color-adjust: exact} .table > table > tr:nth-child(1),.table > table > tr:nth-child(2) {background: #4074b0;} #tableB td:nth-child(2) {width:60%;}");
page.addStyleTag(styleTagOptions1);
//滚屏
autoScroll(page);
Thread.sleep(1000);
PDFOptions pdfOptions = new PDFOptions();
// pdfOptions.setHeight("5200");
pdfOptions.setPath(savePath);
page.pdf(pdfOptions);
} catch (Exception e) {
log.error("生成pdf异常:{}", e.getMessage());
e.printStackTrace();
} finally {
if (page != null) {
page.close();
}
if (browser != null) {
browser.close();
}
}
return true;
}
调用生成 PDF 的方法,将一个微信公众号文章转成 PDF。
public static void main(String[] args) throws Exception {
String pdfPath = "/Users/fengzheng/Desktop/PDF";
String filePath = pdfPath + "/hello.pdf";
JvppeteerUtils.pdf("https://mp.weixin.qq.com/s/MzCyWqcH1TCytpnHI8dVjA", filePath);
}
最终的效果,很清晰,样式都在,基本和页面一模一样。